認証・認可の追加
前記事の予告通り、認証・認可機能を追加した。 本記事ではこの機能に関連する要点をメモしておく。
前提知識
なぜ認証・認可機能が必要なのか
アプリケーションが保持するデータについて、どんな操作をできるかをユーザーの役割ごとに制御したいというニーズはwebサービスでは普遍的だ。 ネット銀行のアプリで考えれば簡単で、口座の残高は本人しか見れないし、本人しか引き出せない。 ただし残高を増やす操作(送金)は本人でなくてもできる。
資源評価に関して言えば、例えば下記のようなケースが想像される:
- 評価対象の系群に関する資源計算や報告書執筆は、主担当者のみができる
- ただし主担当者が業務を継続できなくなった場合には別のメンバーが主担当者として業務を引き継げる
- 副担当者たちは、主担当者の作業結果を外部公開前にレビューできる
- 管理者は、ステークホルダーを代表して提案に対して下記のようなステータスを付与できる:
査読中要再検討受理済
前記事の時点では、ダッシュボード画面が直接資源計算をしていたが、その後の修正で、登録済みの評価結果を参照するように変更していた。 また執筆時点ではまだ資源計算機能は提供していないため、ダッシュボードから読むべきデータがない状態になっている:
資源計算機能がまだないため「データ未登録」が表示されている
では、このデータ登録は誰がやるべきで、誰がやるべきでないだろうか? 主担当者がやるべきであり、通りすがりの一般市民がやるべきではない…というか、できてはならない。
ここで認証・認可機能が必要になる:
- 認証: ある系群の資源計算機能にアクセスしようとしているユーザーが、確かにその操作をする資格のある主担当者であることを確かめる
- 認可: 認証を通過したユーザーに対して、主担当している系群に対する資源計算のみを許可する
このような機能は、ひとつの機能としてはあまり認識されない地味なものかもしれないが、ビジネスプロセス全体が混乱なく流れるための前提といってもよい、不可欠な機能だ。
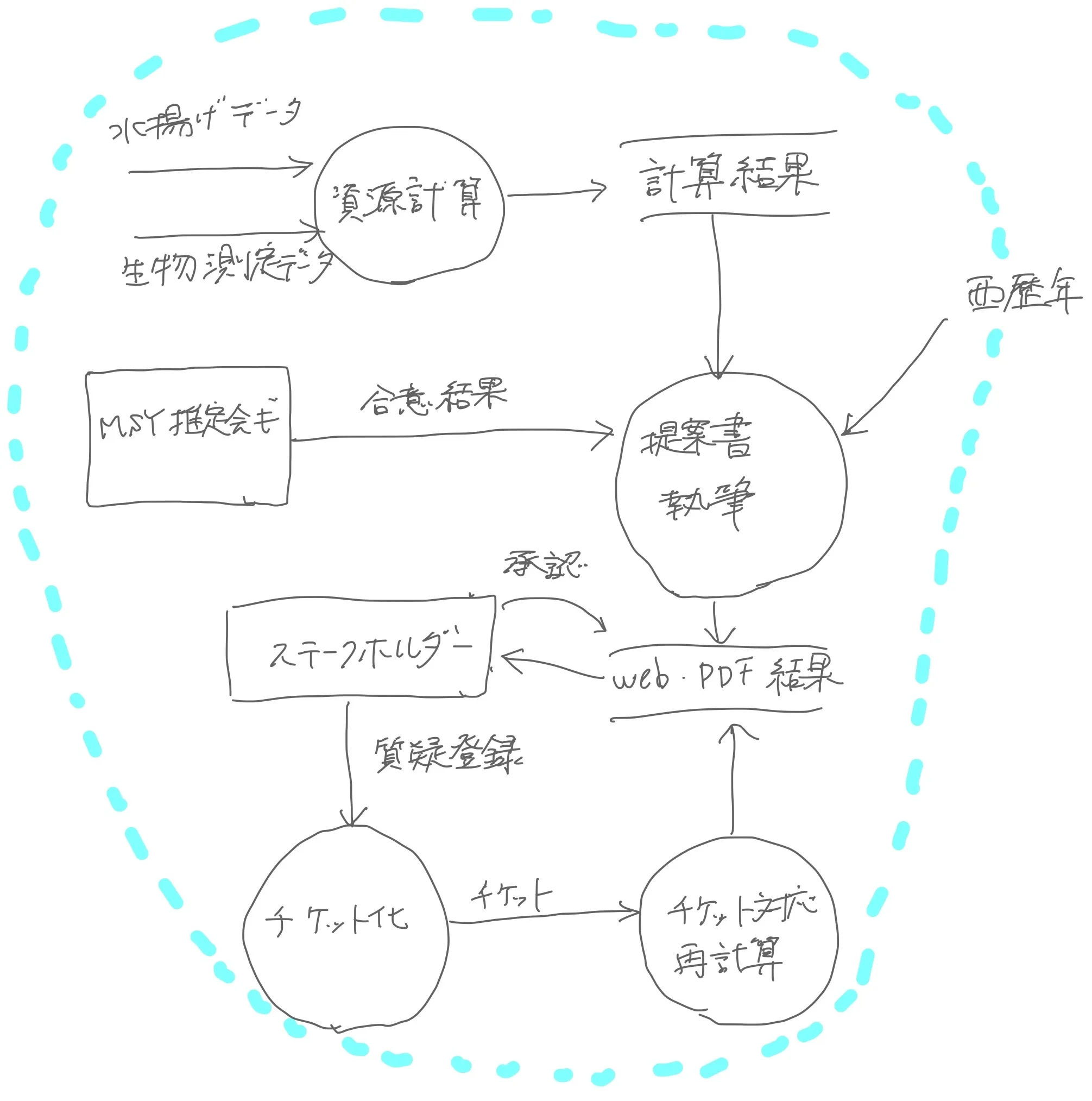
目立たない機能ではあるが、認証はプロセス全体の前提機能である
本機能に関する開発の概要
認証機能に関する技術選定
認証はセキュリティに関わるものなので、不具合があったときのリスクが大きい。 また不具合なく実装するにはコストも時間もかかる。 幸いなことに、現代はこの認証機能自体を商品としている会社がいくつかあり、ゼロから自前実装するよりもはるかに小さい初期投資で使い始めることができる。このプロジェクトではSupabaseを選択した。これは認証専門のサービスではなくデータベースSaaSだが、認証機能もついている。
認可の設計
認可はビジネスロジックの一部なので、SaaSによって「購入」することは難しい。どのユーザーにどんな操作を許可するかをいちいち書くとメンテナンスコストがかかるので、ロールベースの認可を実装することにした。ちょうど資源評価でも、「主担当」「副担当」という言葉があり、これは実質的にロールベースの認可だ。 ということで、まずロール名をモデル化した:
export const USER_ROLES = {
/** 主担当 - 資源評価の主担当者 */
PRIMARY: "主担当",
/** 副担当 - 資源評価の副担当者 */
SECONDARY: "副担当",
/** 管理者 - システム管理者 */
ADMIN: "管理者",
} as const;
次に、認可で操作を制御するデータとして最も認識しやすく重要なものは資源評価対象の系群だったので、系群をSTOCK_GROUP_NAMES としてモデル化した:
export const STOCK_GROUP_NAMES = {
/** マイワシ太平洋系群 */
MAIWASHI_PACIFIC: `${STOCK_GROUPS.MAIWASHI.species}${STOCK_GROUPS.MAIWASHI.regions.PACIFIC}`,
/** マイワシ対馬暖流系群 */
MAIWASHI_TSUSHIMA: `${STOCK_GROUPS.MAIWASHI.species}${STOCK_GROUPS.MAIWASHI.regions.TSUSHIMA}`,
/** ズワイガニオホーツク海系群 */
ZUWAIGANI_OKHOTSK: `${STOCK_GROUPS.ZUWAIGANI.species}${STOCK_GROUPS.ZUWAIGANI.regions.OKHOTSK}`,
} as const;
これらの系群名は、名前と海域を構造化した下記のSTOCK_GROUPS というモデルから生成されている:
export const STOCK_GROUPS = {
MAIWASHI: {
species: "マイワシ",
regions: {
PACIFIC: "太平洋系群",
TSUSHIMA: "対馬暖流系群",
},
},
ZUWAIGANI: {
species: "ズワイガニ",
regions: {
OKHOTSK: "オホーツク海系群",
},
},
} as const;
今思うと、マチ類のように複数種を1資源として評価している資源もあるので、speciesというフィールド名は不適切なことに気づいた。
マチ類も考慮に入れれば、あるべき姿は下記のようになるだろう:
export const STOCK_GROUPS = {
/** マイワシ */
MAIWASHI: {
name: "マイワシ",
species: ["マイワシ"],
regions: {
PACIFIC: "太平洋系群",
TSUSHIMA: "対馬暖流系群",
},
},
MACHIRUI: {
name: "マチ類",
species: ["アオダイ", "ハマダイ", "ヒメダイ", "オオヒメ"],
regions: {
ANAMI_OKIBNAWA_SAKISHIMA: "奄美諸島・沖縄諸島・先島諸島",
},
},
} as const;
ここまでのように定義した部品を使って、Userをモデル化した:
export interface User {
id: string;
email: string;
rolesByStockGroup: Partial<Record<StockGroupName, UserRole>>;
}
複数系群の主担当・副担当を兼ねる実態が反映されている。
将来的に、「兼務は最大◯系群までとする」みたいな規則ができるようなら、その知識をUserモデルに反映すればよい。
以上のような認可に関する意思決定もドキュメントに残しておいた: 0003-user-role-design.md
認証・認可機能の導入
認証・認可を提供するAuthProviderを全ての画面に入れてある。
また認証情報を引き回すためのコンテキストを定義してあるので、認証が必要な操作ではこのコンテキスト経由でユーザー情報を取得することで設計済みの認可を使ってデータ操作を制御できる。
まだ認証・認可機能は画面にしか入れていないのでAPIを追加する場合には何らかの方法でガードする必要がある。
DB構成
本サービスは3つの環境で構成されておりおり、それぞれの環境のデータはDBレベルで分離しておきたい。
認証にはSupabaseを使うことにしたので、productionにはSupabaseを使うとして、developとpreviewをどうするか。
コストを度外視するならそれぞれにSupabaseのプロジェクトを割り当てればよいが、今はそこまで投資する必要がない。
ということで、下記のような構成とした:
production: Supabase(SaaS)preview: in-memorydevelopment: Supabase (Docker 版)
これに伴い、Userに関するDB操作をするためのリポジトリを定義した:
export interface UserRepository {
findByEmail(email: string): Promise<User | undefined>;
findById(id: string): Promise<User | undefined>;
findByStockGroupName(stockGroupName: StockGroupName): Promise<User[]>;
authenticate(
email: string,
password: string,
): Promise<AuthenticatedUser | null>;
getCurrentUser(): Promise<AuthenticatedUser | null>;
logout(): Promise<void>;
onAuthStateChange(
callback: (user: AuthenticatedUser | null) => void,
): () => void;
}
そのうえで、これを利用するSupabase用・インメモリ用の2種類のリポジトリを実装した。
それぞれの環境の環境変数によって、適切なタイプのリポジトリが作られるように、ファクトリを準備した:
export function createUserRepository(): UserRepository {
const useInMemory =
typeof window !== "undefined"
? process.env.NEXT_PUBLIC_USE_IN_MEMORY_USER_REPOSITORY === "true"
: process.env.USE_IN_MEMORY_USER_REPOSITORY === "true";
if (useInMemory) {
return new InMemoryUserRepository();
}
return new SupabaseUserRepository();
}
developではlocalhostを向くようになっているが、productionではSupabaseを向くように、Vercelに環境変数が設定されている。
これらの準備によって、認証機能の利用側では背後の実装を意識せずに、同じ方法で操作できるようになっている:
const login = async (email: string, password: string): Promise<boolean> => {
// 中略
const authenticatedUser = await userRepository.authenticate(email, password);
// 中略
};
DBマイグレーションの準備
production のマイグレーションをするワークフローを GitHub Actions で作り(migrate-production.yml)、初回適用済み。
ちなみに、これの実行タイミングは Vercel でのビルドの前なので、マイグレーション完了から Vercel ビルド完了までの間にユーザーに操作された場合に、データ不整合が起きる可能性がある。 今後、ユーザーに触られる状況が想定されるなら、メンテナンスモードの追加とモードのバリデーションをリポジトリに差し込む必要がある。
シード注入
開発過程では、ロールの違う複数のユーザーを準備しておくと便利なので、シードデータを注入するためのスクリプトを準備してある: scripts/create-users.ts
認証・認可の実装過程で下したその他の意思決定
系群名にはDB側では制約をかけない
ADR: 0006-stock-group-type-safety.md
系群名は管理上の都合で変わる可能性があり、その意思決定の反映には開発者が関与せずにできるようにしておくのが望ましい。 ということで、DB側では系群名の制約は入れず、DBマイグレーションが不要になるようにしてある。 DBスキーマだけ見ると安全性に欠けるように見えるが、ドメインモデルを利用するアプリケーションサービスで操作するように開発すれば、不正な値が入るリスクをなくせるので実用上は問題ない。 …といいたいところだが、実際に、系群名が変わるときに何が起こるか、検討しておいたほうが良さそう(issueを起票しておいた)。
監査ログ
webアプリケーションでよくある監査機能は、資源評価においても有用だ。 具体的な値を参照されるビジネスなので、その値がいつ、誰による変更から導かれたのかを記録できると嬉しい。 ということで、下記のタイミングにおいて監査ログ用テーブルにログを保存することにした。
- データの変更(追加・更新・削除)
- 承認操作(副担当による内部承認・ステークホルダーによる最終承認など)
- 認証イベント(ログイン・ログアウト)
- 権限操作(副担当から主担当への昇格・担当系群の追加など)
これから関連機能を開発するときに、監査ログの書き込みも実装する。
構造化ログの導入
開発時には 「console.log()を入れる」→「マージ前に消す」を繰り返していたが、ログ自体も重要なので、環境変数LOG_LEVELに応じてログを出し分けることにした。
またデバッグを助けるために構造化ログを導入し、ログの情報量と可読性を両立した: 0008-structured-logging.md
まとめ
認証・認可の追加に伴い、DB構成とロール・系群についても設計・実装した。
本記事を書く過程で気付いた不具合もあるが、今回はここまで。
comments powered by Disqus